标题:Federated Learning of Deep Networks using Model Averaging
作者:H.Brendan McMahan (Google), Eider Moore (Google), Daniel Ramage (Google), Blaise Aguera y Arcas (Google)
本文由谷歌提出,开阔了“联邦学习”这一新领域,提出了著名的 model averaging 算法。
- 摘要
- Introduction
- Federated Learning
- Federated Optimization
- Related Work
- The FederatedAveraging Algorithm
- Experimental Results
- Conclusions and Future Work
摘要
首先大概就是现在移动设备可以访问到大量数据,这些数据可以用来学习。但是呢,这些数据可能隐私敏感、数据量大或者同时具备这两种特点。然后本文首次提出了一种分布式移动设备训练一个共享的模型的方法,叫做联邦学习(Federated Learning),这就是联邦学习首次学术上的定义。
本文提出了深度网络的联邦学习,并且对 unbalanced 和 non-IID 的数据具备一定的鲁棒性。此方法允许较少几轮迭代就可以训练一个高质量的模型,这也是联邦学习的一大限制。尽管我们想要优化非凸的loss函数,从多个客户端梯度的平均依然可以有良好的结果,比如可以大大降低训练一个LSTM语言模型的通信开销。
Introduction
随着数据量增大,模型复杂,机器学习有分布式的趋势了。当前有一些分布式优化的模型,但是呢,他们有通信需求,通常只有数据中心级网络结构才能满足这些需求。另外这些模型建立在数据是IID(独立同分布)这个假设之上。相当于总的数据集有一个中心的地方存储训练了。
随着智能手机平板的兴起,并行的趋势来了。终端设备的处理能力已经不错了,天然适合在本地处理隐私数据。通过这些数据学习的模型可以更好地促发先进的应用,但是隐私性又不希望数据被中心节点收集处理。
然后呢本文就研究了让分布式用户共同训练一个模型的方法。这套方法论就叫联邦学习(Federated Learning)。在这个场景中,每个用户(Client)有一个本地训练数据集,这个数据集不上传到服务器。然后每个用户从服务器获取参数并且通过某种方法使得全局模型可以随着本地训练进行更新。
我们提出了 FederatedAveraging 算法,终端用户本地进行SGD训练,然后服务器进行一个模型求平均过程。然后我们用大量实验表明这个方案的可行性。
Federated Learning
什么样的任务很适合FL呢,FL有以下特点:
- 分布式移动设备上数据的训练比中心化训练更有优点;
- 数据量又大又隐私,因此不希望数据可以被统一收集;
- 对于监督类任务,数据的label可以根据用户和他的设备的交互推测。
因此,本文考虑了两个场景:
- 图像分类:比如预测哪一个图片将来可能被多次查看或分享;
- 语言模型:可以改进语音识别和文本输入等。
这一类场景的数据可能是隐私的,这些数据的分布也可能和容易获取的数据集有很大的不同,比如平常使用的语言和维基百科的语法就不太一样了,又或者平常用户的拍照和 Flickr 上面的图片是差很多的。也因此,这些数据对应的label不是可以直接获取的(这也就对应上面特点的第三个,需要能够根据某种模式推测出数据对应的label)。
这些任务都适合用深度学习解决,后面将会考虑联邦学习做这么个事情。同时咱们也希望在大的数据线,不要有太高的通信损耗(Communication cost)。
Privacy for federated learning: FL下隐私有两方面含义,首先,我们需要考虑攻击者可以从模型参数获取什么东西,模型参数也就是不同客户端共同优化的目标。我们目前无法认为这个是安全的,但是在现实场景中,模型参数是由很多个用户共同得到的,此类攻击将会很难部署。
对于真的很隐私的训练任务,可以考虑采用DP去搞这么个事情,但是DP会降低数据效用。还讲了一些其他的东西好像不是很核心。
隐私的另一个含义是攻击者由于可以获取到终端用户的每一次信息更新,那么他可以获取到什么信息。如果终端用户相信server的话,那么可以采用密码学的方式防止此类攻击。当然,也可以采用LDP获取更强的隐私保证,在每一个用户的数据更新过程添加噪声。同时,搞不好MPC也可以有用武之地。
尽管FL和DP没有直接绑定在一起,相对于中心化训练模式,FL也可以提供一定程度上的隐私保护职能。毕竟数据没有出去。安全特效就不仔细分析了。
Advantages for large datasets:当数据量很大的时候,FL拥有天然的优势。对比传统中心化模式,数据需要被传输到中心节点,在FL下,只需要传递参数就可以了。因此,这个communication cost 就很低。
Federated Optimization
FL可以认为是个联邦优化问题,对比传统的分布式优化问题,有着以下不同点:
- Non-IID:不同设备上的训练数据和个人很相关,因此不是独立同分布的数据;
- Unbalanced:类似的,不同用户的数据量可能会相差很大;
- Massive distributed:在真实环境中,我们认为用户的数量远大于每个用户的平均数据量。
本文主要针对非独立同分布以及不平衡数据问题,由于处理这两个问题比较能带来提升。
然后提了一下真实环境中可能会碰到的问题,并说这些问题目前可能是无法探讨的,并假定了一个受限的实验环境,同时也强调了非平衡数据和非独立同分布数据。 假定有 $K$ 个用户,每个用户有一个本地数据集。在每一轮过程中,$C$ 个用户被选择,然后server将当前的模型参数发给这些用户。然后这些用户根据全局状态和本地数据进行更新并把更新发给服务器。通常,对于$n$个数据点,优化过程可以认为是这么个东西:
然后我们假设第$k$个用户的数据用$\mathcal{P}_k$表示,并且$n=|\mathcal{P}_k|$,因此这个优化的目标差不多就是:
在独立同分布下,不同数据的梯度应该满足这么一个性质:$\mathbb{E}_{\mathcal{P}_k}[F_k(w)]=f(w)$,这里把这个单独提出来是因为我们考虑了非独立同分布。实际上我这里有个疑问,就是这里的 $n$ 应该是那一次选的 $k$ 个用户的数据量之和。
然后介绍了一些这个FL部署时候应当注意的事情,比如你不能占用太多网络带宽啊,不能一直计算(一天迭代个两三次就差不多了)啊之类的。可以理解,毕竟你在用户手机上搞这些影响用户体验是不行的。在这些操作受限的情况下,可以通过提高并行化(提高训练的用户量)或者提高数据计算复杂度(在每一次迭代过程中算更复杂的东西)来提升。
Related Work
列了一些参考文献和类似的工作。
The FederatedAveraging Algorithm
首先大概讲了SGD这个算法很基础但是也很重要。然后说SGD也能被用到FL中进行优化,每一轮迭代用一个 minibatch 进行梯度计算就好了。就是需要很多次的迭代。
我们把本文的算法叫做FederatedAveraging(FedAVG)。计算量由以下几个关键参数控制:参数 $C$ 表示每一轮选取的用户比例;$E$ 应该就是表示epoch;以及参数 $B$ 表示minibatch大小。如果用户本地的数据集被用作一个单一的minibatch,那么就写成 $B=\infty$。
SGD一个简单的实现就是,给定学习率,用户 $k$ 根据本地数据计算 $\triangledown F_k(w_t)$。由于$\sum_{k=1}^{K} \frac{n_k}{n}g_k = \triangledown f(w_t)$,模型可以更新为:
等价的更新也可以这么给出:
也就是说,终端用户根据当前模型利用本地数据更新一轮,然后服务器根据权重对总的模型进行更新。算法1就是一个具体的联邦学习算法。当算法这么写的时候,一个很自然的额问题就是在服务器同步的时候,终端用户本地迭代了很多轮了($w^k \leftarrow w^k -\eta \triangledown F(w_t)$)该怎么办。对于一个有 $n_k$ 条数据的用户,每一轮本地更新中迭代的次数是$u_k=E\frac{n_k}{B}$。完整的伪代码如算法1所示。

显然,对于非凸的优化目标,这个模型可能会产生很不好的结果。根据Goodfellow等人的方法,我们对两个MNIST模型汇聚的时候出现了比较差的效果(二者拥有不同的初始条件,如图1左图所示)。
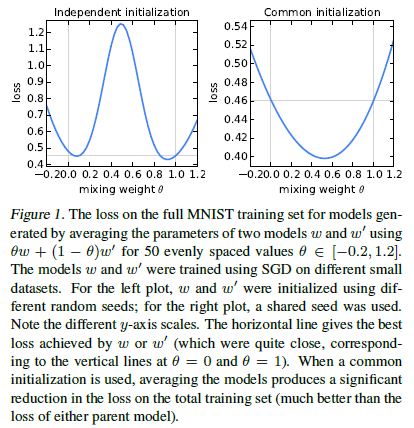
然后,现有工作表明,充分参数化的神经网络可以表现出比较好的性能,比我们所认为的更不容易出现坏的局部极小值。而且,当对不同的模型进行相同的随机初始化的时候,这个averaging模型效果还不错(参考图1右图)。二者参数的平均$\frac{1}{2}w + \frac{1}{2}w’$的 loss 比同一个数据集训练要更小。
dropout training 的成功好像也可以解释咱们这个模型为什么好,但是我不太懂dropout,要是以后了解了有机会再回顾这里。
Experimental Results
到这里算法就介绍完了,好像是个超级简单的算法。然后这里以图片分类和语言建模任务为例展示了两个FL的应用场景。对于每个任务,作者选了一个数据量较大的代理数据集,这样可以更全面的观测FedAVG中超参数的影响。由于每个用户的训练过程较简单,作者选了2000个用户。然后研究了三个FL模型,或者FL任务。
- MNIST手写数字识别任务;
- 2个隐藏层,每层200个神经元,用ReLu激活的神经网络(一共有199,210个参数需要学习),表示为MNIST 2NN;
- MNIST上用了5x5卷积层的CNN模型,一个全连接的512个神经元,用ReLu激活函数,最后输出到一个softmax层,一共有1,663,370个参数。
此外,为了了解联邦优化的过程你,我们也需要知道数据在不同的用户client那儿的分布是咋样的,本文考虑了两种情况:
- IID:总的数据被 shuffle 然后依次分给100个用户;
- Non-IID:数据按招标前排序,然后分成200堆,每堆数据300个,并给每个客户分配2堆数据。这个是很Non-IID了,因为大多数用户只有2个数据。
为了测试语言模型上的联邦优化能力,本文用《莎士比亚全集》构建了数据集。作者为每个剧本中的每个角色(要满足至少有两行数据)构建了一个客户端数据集,这就产生了1146个客户端。对于每个客户端,作者将数据划分成了一系列训练行(前80%)和测试行(后20%行)最终的训练集中有3,564,579个字符,测试集中有870,014个字符。这个数据集本质上是不平衡的,大多数角色只有很少数的行,少数角色有很多行。此外,测试机并不是随机分布的。采用identical train/test spilt(我并不知道这是啥),作者也构建了一个平衡的IID版本的数据集,也是有1146个客户端。
在这个数据集上,作者训练了一个字符级别的LSTM语言模型,其核心任务是读了一行中的每个字符之后猜测下一个字符。这个模型读一系列字符作为输入,然后把每个字符embed到一个8维向量,这些向量被输入到2个LSTM层,每层有256个节点。最后第二个LSTM层的输出送到了一个softmax输出层。整个模型有866,578个参数。
SGD对学习率 $\eta$ 很敏感,因此实验结果都是基于一系列的学习率的,大概用了11-13个不同的学习率,间隔在$10^{-3}$和$10^{-6}$。然后也发现了最优的学习率不会像其他参数一样变化那么明显。
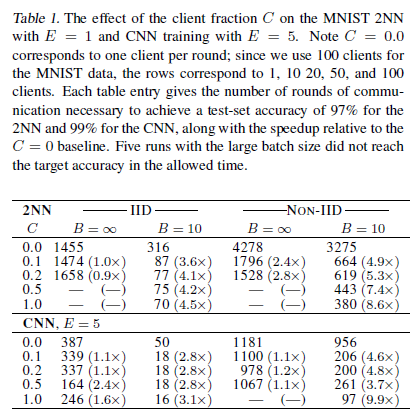
Increasing parallelism:首先研究了参数 $C$ 的影响,这个参数控制了客户端数量。表1表明了不同参数 $C$ 下 MNIST 模型的实验结果。
出于展示目的,作者也构建了学习曲线,如图2所示。淡灰色的线是啥我好像也没理解透。
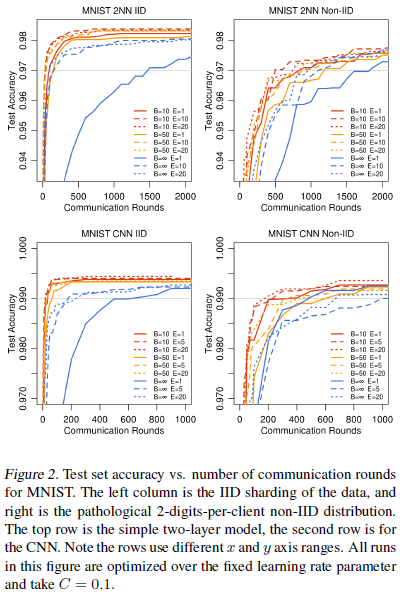
当$B=\infty$ 的时候,也就是MNIST数据集把600个客户端的数据视作单一batch,添加 $C$ 仅仅有很小的提升。采用较小的 batch size $B=10$的时候,$C>0.1$ 时效果有很大的提升,尤其是对于 Non-IID 的情况。所以后面的实验就设置$C=0.1$了。后面还设置了一系列其他实验,由于我呢也不懂,就目前没有仔细看了。
Conclusions and Future Work
本文表明FL是个很牛逼的东西,可以在相对较少的迭代次数下训练不错的模型。当然本文只在SGD上面进行了探讨,在其他优化模型上也需要进行进一步研究,比如AdaGrad、ADAM;在助于优化的模型结构上也期待进一步研究,如dropout、batch-normalization等。
个人总结
所谓的 Federal Averaging 算法就是最基本的SGD算法,我们知道本地SGD的核心其实也只是对每个数据算梯度,FL 下,算梯度还是那个过程,只不过拥有数据的人算而已。
本篇内容到这里就结束了,欢迎关注公众号《差分隐私》,获取更多前沿技术。


